CSS Compatibility Checker – Votre allié pour un code parfaitement compatible avec tous les navigateurs
sympa, on gagne du temps... ou alors il suffit de s'en foutre en mode ça marche sur mon ordi...











sympa, on gagne du temps... ou alors il suffit de s'en foutre en mode ça marche sur mon ordi...
Histoire de bosser un peu sur l'utilisation d'Imagick (pour lequel je m'étais fait des notes ici 12) j'ai essayé de faire une petite «api» de génération de badges simple.
On peut appeler l'api directement en précisant les variables suivantes:
?txt=trop beau|pas vraiapi.warriordudimanche.net/badgit/?txt=Mon%20super%20badge&backcolor=red&txtcolor=&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge&backcolor=red|pink&txtcolor=pink|red&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge|de%20ouf&backcolor=red|pink|maroon&txtcolor=pink|red&icon=&font=montserrat.ttf&fontsize=16
api.warriordudimanche.net/badgit/?txt=Mon%20super|badge%20|de%20ouf%20&backcolor=red|pink|maroon&txtcolor=pink|red&icon=|fontawesome_solid/smile-beam.svg|fontawesome_solid/hand-back-fist.svg&font=montserrat.ttf&fontsize=16

J'ai goupillé aussi un petit front basique, histoire de ne pas se taper tout au clavier.

Ça ne servira sans doute à personne mais bon, sait-on jamais 
Ceci dit, il y a une classe badge qui peut faire l'affaire quelque part...
Le code est là : https://api.warriordudimanche.net/badgit/?download


Heu, sinon j'avais fait ce truc là il y a un moment... https://api.warriordudimanche.net/qr/
On peut lui passer une chaîne de caractères et il génère le Qr code, il y a un frontend (minimaliste) et il permet de faire un bookmarklet... ça utilise http://phpqrcode.sourceforge.net.
C'est en PHP, c'est auto hébergeable sans docker 

Si ça intéresse quelqu'un, pour le zip, c'est par là, c'est cadeau : https://api.warriordudimanche.net/qr/?download
Je colle ici la mini doc que j'avais faite:
returns a qrcode png image
txt: the qrcode content
version: displays this api's version
download: downloads the php api file
this: returns a qrcode of the referer url
example: api.warriordudimanche.net/qr/?txt=loremipsum
uses: http://phpqrcode.sourceforge.netDepuis que mon grand est en fac d'info, on a un nouveau sujet de conversation et j'ai ENFIN un interlocuteur dans le domaine à la maison !
Du coup, il arrive le weekend avec les TP qu'il a eus pendant la semaine et me pose des questions sur les difficultés qu'il a.
En ce moment, il commence PHP et CSS/HTML...

Du coup, aujourd'hui, il travaillait sur la page de login pour le projet final, une todolist en PHP+HTML+CSS sans JS.
Il voulait faire des labels flottants parce qu'il avait vu que c'était joli... Comme il découvre le monde merveilleux du frontend, on s'y est mis à deux et on a improvisé un petit cours.
Il a appris les subtilités du ciblage, les pseudo éléments, l'usage de :not() et :has()...

Pour la page de démo: c'est par là.
Pour le code : c'est sur snippetvamp.
En gros, on veut que le label soit dans l'input, comme un placeholder, lorsque il est vide mais que le label reprenne une place normale lorsque l'utilisateur clique dans l'input pour le remplir.
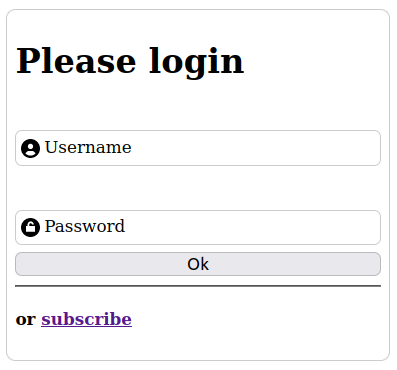
<label><span>Username</span>
<input type="text" name="login" value="" placeholder=" " >
</label>Ensuite, je déplace le span vers l'intérieur de l'input:
label span{
position: relative;
top:2em;
left:24px;
transition:all 500ms;/* et on fait une transition douce, merci*/
}Puis on utilise :has() pour cibler le span du label contenant un input ayant le focus.
label:has(input:focus) span
{
color:grey;
top:0;
left:0;
transition:all 500ms;
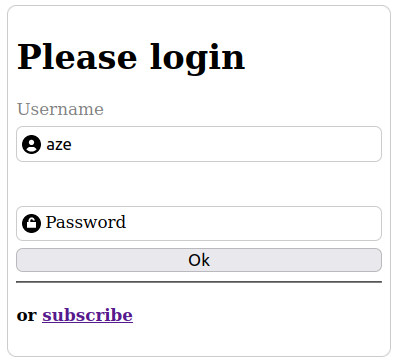
}À ce stade, quand l'utilisateur clique dans l'input, le label glisse vers le haut pour sortir de l'input.
Toutefois, le problème c'est que lorsque l'input perd le focus, le label revient à l'intérieur même si l'input a été complété... et les deux textes se chevauchent hideusement...

La logique voudrait qu'on cible alors le span du label contenant un input vide, genre avec input[value=""] ... sauf que ça ne marche pas car le fait de remplir un input ne modifie pas l'attribut value de la balise input...

Puisqu'on ne peut pas cibler un changement de l'attribut value, on peut cibler... le placeholder ! Enfin... styler en fonction de la visibilité du placeholder...
Ainsi, en utilisant :placeholder-shown, on peut ajouter une règle de ciblage au CSS précédent:
label:has(input:focus) span,
label:has(input:not(:placeholder-shown)) span
{
color:grey;
top:0;
left:0;
transition:all 500ms;
}Et là, les plus observateurs d'entre-vous - qui se demandaient avec une angoisse et un mépris non dissimulés pourquoi j'avais collé un placeholder=" " dans mon HTML - comprennent l'astuce: si le placeholder est visible, c'est que l'input est vide...
Et ça marche, tout est supporté dans la plupart des navigateurs. En plus, c'est léger, ne demande pas une structure HTML alambiquée ou des règles CSS à la mords-moi le zboub...
Si ça peut servir, c'est cadeau
Une bibliothèque de plus de 3000 éléments d'UI...
Je mettrais mon nez là-dedans un jour... il doit y avoir beaucoup à apprendre rapidement en auditant ces snippets...
Un jour...
API ouverte de traduction automatique, auto-hébergée, mode hors ligne, facile à configurer.
Je me note ici pour une prochaine fois parce que fetch n'est pas forcément très intuitif...
fetch("index.php", { method: 'POST', body: formData })
.then((response)=>{
// on attend l'arrivée de la réponse et on la traite
return response.text(); // ou response.json();
})
.then((text)=>{
// on attend la fin du traitement de la réponse et on en traite le contenu
console.log(text);
});En gros, on crée une fonction asynchrone pour pouvoir utiliser les await.
const fetchAPI = async(URL) => {
const response = await fetch(URL); // on attend l'arrivée de la réponse
const data = await response.json(); // on attend la fin du traitement de la réponse
console.log(data)
}
fetchAPI("https://jsonplaceholder.typicode.com/todos/1")Pas mal cette astuce ! On peut avoir des conditions qui prennent en compte un élément parent ou un élément frère pour cibler un élément...
p:is(h2 + *) : seulement les paragraphes directement après un H2p:not(blockquote *) : les paragraphes ne se trouvant pas dans des blockquotes...Ça peut carrément simplifier certains cas !
OMAGAD ! Le print('coucou2') m'a tué !

Ménon... Mais dites-moi que c'est pas vrai...
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<svg xmlns="http://www.w3.org/2000/svg" width="500" height="500">
<circle cx="250" cy="250" r="210" fill="#fff" stroke="#000" stroke-width="8"/>
<script type="text/javascript">alert(1);</script>
</svg>Donc, si on colle du JS dans un SVG, le JS serait exécuté à l'affichage de l'image ?!
Je teste ci-dessous avec l'exemple donné sur la page...

Sur mon site, l'image s'affiche normalement sans exécuter le code... par contre, si on ouvre l'image dans un autre onglet...
Comment c'est possible de laisser un truc pareil dans la nature ?!

En ce moment je bosse sur l'appli de documents/exercices que j'utilise en cours (cf https://warriordudimanche.net/article1686/lappli-documents-que-jai-codee-pour-taf pour mémoire).
J'implémente toute une nouvelle rubrique et de nouveaux items afin de couvrir le spectre de l'expression orale de façon simple en ajoutant une sorte de labo de langue simplifié.En gros, je veux que le gamin puisse travailler à l'écoute de mots modèles mais également qu'il puisse s'enregistrer et se réécouter simplement et quelque soit le support...

Les frontend qui me lisent voient de suite où ça va couiller (merci les copaines)
Et oui, j'ai codé un truc qui fonctionne très bien, relativement propre et simple, facile à utiliser... sous Firefox, opera, vivaldi, chromium et sous Android.
Hélas, ma solution utilise l'API MediaRecorder qui semble présenter des difficultés sous certains navigateurs, vous devinez lesquels...
J'ai testé sur safari (enfin epiphany passque j'ai pas d'apple sous la pogne, tu te doutes...) et ça refuse de fonctionner, vu que MediaRecorder y est bloqué pour nôôôtre saicuritay...
J'ai ensuite testé sur Edge avec mon portable et ça n'a pas fonctionné... toutefois, quand j'ai installé le deb d'Edge sur mon linux ⬇⬇⬇ ...

...là, ça a fonctionné... Mais si ça marche, ça doit venir de Linux et pas de Edge (mauvaise foi inside )
Donc en gros, on revient à des soucis de compatibilité avec le nouvel IE ?! (ouelcome to aoueur fanne tasse tique taïme meuchine !)

Pourtant, canIuse me dit que ça devrait fonctionner, même sous Safari:

Bon, avec le navigateur à la pomme, il y a bien une manip à faire dans la configuration avancée pour les devs qui pourrait débloquer la situation mais je me vois mal demander ça à des élèves qui éprouvent déjà des difficultés non négligeables à discerner la barre d'adresse ou qui peinent - la sueur au front - à taper une majuscule sans passer par la touche de verrouillage...


Donc, là, pour le moment, rien à faire dans l'immédiat pour utiliser simplement MediaRecorder avec safari ou Edge... j'ai donc opté pour une «solution» temporaire: en cas d'absence de l'API, j'ajoute une classe spécifique et je disable les recorders de la page, puis j'affiche un message d'avertissement avec des liens vers des navigateurs compatibles (firefox et forks en tête)...
Après, j'ai bien trouvé un polyfill qui pourrait faire le job ( https://github.com/ai/audio-recorder-polyfill ) mais je ne l'ai pas testé, c'est un peu lourd à installer et pis... c'est pas moi qui l'ai fait... 
Il y a de ces trucs en CSS quand même...
Quelques notes perso ici...
Pour modifier une grid par exemple...
main:has(> :nth-child(5)) {…}Pour appliquer un darkmode
html:has(#dark-mode:checked) {…}form:has(:user-invalid) .error {
display: block;
}Et moi qui pensais que ce n'était réservé qu'à des sass & consorts !
Voilà qui permettra de mieux organiser le code et le rendre plus lisible...
/*AVANT*/
.nesting {
color: hotpink;
}
.nesting > .is {
color: rebeccapurple;
}
.nesting > .is > .awesome {
color: deeppink;
}
/* MAINTENANT*/
.nesting {
color: hotpink;
> .is {
color: rebeccapurple;
> .awesome {
color: deeppink;
}
}
}[EDIT] Par contre, ce n'est pas forcément supporté par les navigateurs pas à jour... https://caniuse.com/css-nesting
en gros, pour rendre plus homogène un texte sur plusieurs lignes... Attention, pas pour un texte de plus de 10 lignes apparemment.
scrollIntoView() ➜ https://www.alsacreations.com/astuce/lire/1883-Le-scroll-maitrise-avec-scrollIntoView.htmlUn petit résumé perso de cette page sur l'objet FormData en javascript.
let form = document.querySelector('form');
let data = new FormData(form);['clé','valeur']for (let entry of data) {
console.log(entry);
}ou
for (let [key, value] of data) {
console.log(key);
console.log(value);
}for (let key of data.keys()) {
console.log(key);
}let title = data.get('title')let titles = data.getAll('title');data.set('date', '2022-12-25');
data.append('tags', 'vacations');
let hasID = data.has('id');
let arr = Array.from(data.keys());let arr = Array.from(data.values());let serialized = Object.fromEntries(data);
let obj = {};
for (let [key, value] of data) {
if (obj[key] !== undefined) {
if (!Array.isArray(obj[key])) {
obj[key] = [obj[key]];
}
obj[key].push(value);
} else {
obj[key] = value;
}
}let stringified = JSON.stringify(obj);
{kind=link}