Il y a quelques jours, lassé de reprendre à zéro à chaque fois que je dois faire un truc avec GD sur PHP, je me suis dit que je pouvais faire une classe pour ça. Comme, exceptionnellement, j'avais un peu moins de deux heures de tranquillité, je m'y suis collé.
Au bout du compte, une fois la classe codée, il faut bien la tester...😬
C'est le problème des codeurs : ils ont du mal à arrêter de coder 🤩. Du coup, me voilà en route pour un script exploitant pictools.php... et ce qui aurait du prendre deux heures a pris plusieurs jours de papa codeur (petit rappel: 1 h de papa codeur = 7,2 heures de codeur normal en zone de guerre, au cours actuel 💣)
Bref, j'ai donc pondu une «api» avec un frontend permettant d'appliquer des transformations à une image à partir de son URL.
😎 petite image, long discours, toussa.
Donc, on fournit l'URL de l'image puis on ajoute des actions les unes à la suite des autres. Certaines n'ont pas besoin de paramètres (emboss, sepia etc) et d'autres si (contrast, resize etc)
Quand on clique sur un bouton action, on ajoute cette action à la liste avec, le cas échéant, l'input qui va bien pour les paramètres avec un placeholder de rappel.
Ainsi, on peut resize l'image à une taille précise ou à un pourcentage de la taille normale: tous les paramètres de coordonnées et de taille peuvent être précisés en pixels ou en pourcentages.
De plus, si on veut redimensionner l'image à une largeur en conservant le ratio automatiquement, il suffit de mettre -1 à la place de la hauteur: le script se démerdera tout seul.
La config ci-dessus donne le résultat ci-dessous:
L'image d'origine
Le résultat donné par scriptopic
Mais c'est pas tout
Donc, scriptopic permet de retoucher une image automatiquement. OK.👍
Mais cette image est utilisable directement depuis son URL de génération: si on colle l'URL précisée dans le cadre résultat, ça fonctionne. Avec un peu d'habitude, on peut le faire en direct (genre pour une image d'en-tête...). Comme les images retouchées sont
sauvegardées avec un hash de l'url de requête, si on l'appelle à nouveau, elle ne sera plus générée mais simplement renvoyée (visible soulagement du serveur )
Et aussi
Comme des fois on a la flemme de faire une balise image, Scriptopic vous la donne directement: un double-clic et c'est copié prêt à coller...
Mais ce n'est toujours pas tout... (vous êtes gâtés)
Un truc rigolo, c'est que, comme pour Stamp, le front de scriptopic génère un bookmarklet en temps réel (c'est la deuxième ligne du cadre résultat): une fois satisfait de votre script, le bookmarklet généré permet de l'appliquer à l'image en cours: vous ouvrez l'image dans un onglet et clic-clac merci kodak.
Si vous voulez simplement envoyer l'image en cours pour travailler dessus, le bookmarklet de base est dispo en footer.
Atta atta, pars pas j'ai pas fini
Histoire d'ajouter encore une feature, vous pouvez stocker des scripts, à la main, dans le dossier ... scripts/ . Vous utiliserez le nom du fichier dans l'url avec ?script=[nomdefichier]
Ainsi, en sauvant le json de l'exemple (cadre «Script au format JSON») dans un fichier scripts/sepia.json vous pouvez ensuite l'appeler avec&script=sepia
Vous pouvez vous faire une bibliothèque de scripts pour tout et les appeler directement au lieu de vous taper du json dans l'URL
Je n'ai pas nettoyé le code, vu que je subis un harcèlement constant à la maison (lol), mais je le ferais, promis ! Le tout est en beta à l'arrache en licence amusez-vous avec.
Je n'ai pas encore écrit de doc pour pictools_class.php qui se trouve dans le zip, mais c'est assez simple à utiliser et chaque méthode est «documentée»
$picture=new pictool();// on peut mettre un array contenant les valeurs initiales des attributs : ['format'=>'png'] par exemple)
$picture->load('www.moncul.sur/la_commode.jpeg');
$picture->contrast(20);
$picture->sepia();
$picture->save("fichier.jpeg");
$picture->display();
Le script matrix qui alterne sketch et gaussian à plusieurs reprises puis colorise en vert
Pas flippant du tout.
Todo
Débugger, vu que ça va se dévoiler à l'usage plus intensif
ajouter le listage et l'usage des scripts sauvegardés dans le front.
Comme toujours, le bookmarklet vous permet d'envoyer l'URL courante à Stamp: ouvrez l'image dans un nouvel onglet et cliquez sur le bookmarklet.
pour les plus observateurs
Bande de coquins, vous avez sans doute remarqué un autre bookmarklet à côté du premier... c'est un bookmarklet dynamique: grâce à lui vous pouvez créer des bookmarklets avec un texte spécifique.
Par exemple, si vous envisagez d'utiliser souvent le tampon «dans ton cul», pourquoi le retaper à chaque fois ? Glissez ce lien dans la barre de favoris et let's the fun begins !
Comme d'hab
Fait à l'arrache, interrompu toutes les minutes mais avec amour, dévotion à l'absurdité du monde et mon ordi.
Tiens, je ne savais pas que la bibliothèque GD avait une fonction imagecreatefromstring() qui permet de créer une ressource image à partir d'une chaîne.
C'est très utile dans le cas où on récupère une image via une URL sur un site et qu'on veut lui appliquer un traitement.
En effet, quand on veut faire ça «normalement», on a recours à imagecreatefrom[FORMAT] (imagecreratefromPng() par exemple), ce qui oblige à connaître l'extension ou au moins le type mime de l'image... et des fois, ça couille : l'URL ne contient pas l'extension ou alors il y a des paramètres GET dedans, bref, ça fait chmir.
Avant, je partais vers la récupération de l'extension du fichier pour appeler la fonction adaptée... c'est chiant, sale et pas parfait comme solution (bugs de nom et besoin de télécharger localement l'image sous forme de fichier)
Ainsi, Gilles me fait passer une adresse de métamoteur de recherche d'ebooks ( https://recherche-ebook.fr/ ) tout en notant que ce serait bien de faire une version qui soit plus propre... (pas de JS, de redirections, de pubs etc..)
écoutez Thérèse, comme la vie est savoureuse, n'est-ce pas...
Il se trouve que je m'étais fait un script dont le but était justement de charger des urls, de les parser, de récupérer et d'organiser du contenu.
Pour faire simple, on crée des «profils» correspondant à une série d'URL avec la regex de parsing et le template correspondants. Il suffit alors d'appeler le profil pour obtenir une page de résultats mise en forme.
Comment ça marche ?
on accède au script : ?p=<profil>
slurp accède au fichier de configuration du profil dans packs/<profil>.php
pour chaque url du pack, il charge la page, la parse, met en forme les données dans le template
Le pack est un array du type:
$packs['<profil>']=[
[
'url'=>'http://urltoparse.com/',
'pattern'=>'REGEX PATTERN with (?<name>..) capture',
'template'=>'<li> HTML Template where data is inserted to : use %name% '
],
[
'url'=>'http://urltoparse.com/',
'pattern'=>'REGEX PATTERN with (?<name>..) capture',
'template'=>'<li> HTML Template where data is inserted to : use %name% '
],
];
Dans le template de chaque url,
on peut utiliser %variable% pour placer les captures regex : (?<title>[^"]*?) ➜ %title%
deux variables sont toujours accessibles:
%ROOT% pour accéder à l'url du pack
%DOMAIN% pour accéder au domaine de cette url (pour compléter une URL relative par exemple)
J'ai ajouté la possibilité de créer un dossier au nom du pack contenant un header et un footer pour qu'on puisse faire un site à partir d'un profil.
packstemplates/<profil>/
J'ai ensuite créé un pack contenant les principaux sites d'epubs, cherché les patterns regex...
J'ai ajouté les icônes Lucide ( https://lucide.dev ) à iconeleon. comme pour les autres packs d'icône, on peut en changer la couleur via le select qui va bien.
Bisou !
Créer une impression de hasard (dans les formes, couleurs ou tout ce qui peut être stylé en css) en utilisant :nth-of-*() pour changer des variables css.
En utilisant assez de variables et en utilisant des nombres premiers pour nth-of, on donne l'illusion de la randomisation. Intéressant.
Bon, je ne vous cache pas que c’est long niveau processing et je ne pense pas que ce sera vraiment utilisable pour de l’application web grand public. Mais c’est rigolo.
rien d'essentiel ne doit dépendre de javascript, en particulier les formulaires.
JS peut être désactivé
le navigateur peut être obsolète (oui, windows, c'est de toi que je parle)
des extensions peuvent bloquer le script
le client a peut être une connexion lente qui va timeout
le client a peut être une connexion intermittente (genre le train)
il peut y avoir un firewall qui bloque certaines choses.
etc
En gros, JS devrait être réservé à des choses qu'on ne peut pas faire autrement et/ou non essentielles.
Pour les formulaires, on peut partir d'un formulaire normal fonctionnant normalement et l'améliorer via JS: capturer l'événement onsubmit et gérer l'envoi au serveur via des promises et fetch, traiter les erreurs etc.
Si JS ne fonctionne pas, le formulaire continuera de faire son job avec le comportement par défaut de submit mais de façon moins sexy, c'est tout.
Et si les envois et retours se font en JSON et tout le merdier ?
Problème de type de retour et de format de réception
L'auteur propose d'utiliser le header côté serveur pour identifier qui de JS ou de HTML est à l'origine de la requête (avec Sec-Fetch-Mode par exemple ) et ainsi adapter le comportement du serveur (traitement des données et composition de la réponse)
En gros:
si ça vient de JS ➜ gère le JSON et renvoie du JSON pour que JS gère la réponse
si ça vient de HTML ➜ gère le formulaire normalement et renvoie une nouvelle page HTML composée côté serveur.
Ça fait un moment que je parle de certaines de mes applis au fil de billets ou de commentaires, en particulier de celle que j'utilise au boulot. Un très long billet totalement dispensable destiné à ceux que l'enseignement intéresse (ou les logiciels dans l'enseignement)
Je me suis dit que ça pouvait intéresser des gens de voir avec quoi je taffe.
Les attentes (le pourquoi du comment j'ai décidé de faire mon propre truc)
Tout est venu de l'aspect pour le moins instable et aléatoire des logiciels et environnements proposés dans le cadre de mon boulot que ce soit au niveau du ministère, de l'académie, du département ou même du collège.
1- du problème des évolutions 👎
En gros, on change soit de logiciel soit d'environnement soit de machines à peu près tous les ans ou les deux ans, ce qui induit une certaine appréhension au niveau de la conservation de nos données: les exercices réalisés dans les exerciseurs disparaissent, les données et documents de l'ENT également... bref: c'est du taf inutile à se retaper tous les ans (ou deux ans) 💩
2- du problème des logiciels 👎
Mon autre souci, c'est que les logiciels proposés sont rarement utilisés par ceux qui les codent puisqu'il s'agit d'applis à caractère administratif (appel/cahier de texte etc) ou pédagogiques (exerciseurs / stockage de données / expos etc)
Résultat, l'UI est merdique et il est impossible de faire la moindre opération sans un nombre de clics qui à lui seul justifierait qu'on vire le bureau d'études. Quand tu dois swapper clavier souris trois fois pour juste une case à cocher, on a un problème. 😬
Ce problème vient du fait qu'à vouloir donner la possibilité de réaliser des choses complexes, on complexifie inutilement la réalisation des choses simples... or, on fait plus souvent des cases à cocher ou des cases de texte à remplir que des formulaires insérés dans des vidéos. 😭
3- de mes attentes persos quant aux applis
Pour ma part, j'attends d'une appli destinée aux élèves et aux professeurs que:
Pour les élèves:
la consultation et les exercices se retrouvent sur la même plate-forme et dans des espaces clairs
les élèves n'aient pas à se logger pour pouvoir consulter ou s'exercer ( limiter la friction de travail selon mon adage: «si c'est galère il va pas le faire» 😅)
ça passe partout y compris et surtout SUR LEUR PITIN DE TELEPHONES ! Quand tu vois l'ENT sur mobile, ça te donne des envies de suicide collectif.
que ce soit clair, lisible et simple.
que tous les documents / pdf etc utilisés lors d'un cours soient dispo depuis un seul lien de partage
Pour moi:
pas de perte de temps au moment de mettre en ligne: je copiecolle le lien de partage de mon document dans l'ENT et c'est tout.
pas de perte d'énergie au moment de réaliser les documents et travaux (limiter la friction d'usage selon mon adage «la vie est trop courte pour se faire chier deux heures sur un document»)
mise en ligne rapide et simple des documents (et possibilité de partager des documents sur une page sans la réaliser vraiment: génération auto de la page de partage)
pas de perte de mon boulot: c'est sur mon serveur, pas sur une merde académique hébergée aux USA qui va se perdre ou être fliquée.
pas de flicage ni de moi ni de mes élèves.
rapidité et simplicité de la création d'exercices
Naissance de Documentos
Il s'agit d'une appli en ligne de consultation libre des documents utilisés en cours.
Côté élève, un lien de partage conduit à la page que j'utilise en classe pour faire cours: il a donc toutes les ressources pour revoir la leçon ou récupérer le cours en un seul lien.
Cette même page me permet de mettre une image en plein écran en un clic, de faire plusieurs diapos simplement etc.
Côté enseignant, elle fournit un explorateur de fichiers , un éditeur de pages etc. On peut ainsi créer un nouveau dossier de travail pour les 5ème, y déposer en une fois mp3, images etc, y créer une page dans laquelle on organise le tout et même créer des exercices numériques sans que ça prenne plus de temps de le faire là que de le faire sous libreoffice (souvent, la version papier me prend grave plus de temps que la version numérique en fait 😅)
Ok, mais ça a quelle tronche ton truc ?
La racine de la page d'accueil donne accès à tous les niveaux
et dans chaque niveau, une page unique liste tous les documents disponibles. Quand le prof cherche le document du jour, il peut filtrer en tapant une partie du nom du dossier contenant lesdits documents.
Une fois sur le document, l'élève (ou le prof en classe) a une page claire avec documentation, questions, liens vers les fiches de révision et pdf éventuellement distribué.
L'enseignant peut également ajouter des éléments de formulaire dynamiques permettant de sélectionner, cocher, ordonner, compléter
Vous noterez au passage qu'on peut ajouter un bouton permettant de se rendre directement à un temps T d'une vidéo ou d'un enregistrement, pour guider les élèves.
J'ai ajouté un bouton servant à changer la police de caractères pour l'opendyslexic:
Et côté admin alors ?
Le prof a un filemanager pour créer des dossiers et des fichiers simplement, uploader en glisser-déposer, éditer des fichiers. L'accent a été mis sur la rapidité et la simplicité d'utilisation.
Si on se contente d'uploader sans mettre de page, le lien générera une page complète avec les documents. Sinon, on ajoute une page html qu'on édite ensuite (deux clics)
Tous les fichiers constituant un «document de classe» se trouvent dans le même dossier par défaut: si on crée des sous-dossiers dans celui du document, chaque sous-dossier devient une diapo indépendante générée comme des pages individuelles. Lorsqu'on se rend sur la page de partage, on passera de l'une à l'autre avec les flèches du clavier ou celles apparaissant sur les côtés de l'écran... pas besoin de se faire chmir à créer les diapos, les lier que sais-je.
On a donc: ROOT> niveau> document> fichiers ou ROOT> niveau> document> diapo1>fichiers , ROOT> niveau> document> fichiers>diapo2>fichiers etc.
Et la réalisation d'exercices alors ?
Pour la mise en page, on utilise markdown, donc, du texte brut. Hors de question pour moi de devoir me prendre le chou avec des mises en page compliquées.
Sur ce principe, pas de boîtes de dialogue, de clics multiples pour créer des exos: tout se fait par deux types de «balises» sans lâcher son clavier:
les {{}}
Propres à mon framework perso, je les ai adaptées à Documentos:
pour insérer un fichier à un endroit: {{fichier.ext}} et c'est tout.
pour insérer tous les fichiers d'un type {{*.jpg}}, et si on ne se souvient pas bien du nom {{*moncul.jpg}} fonctionne très bien.
pas de boutons ou balises spéciales selon les documents: documentos se démerde seul... ainsi {{fichier.jpg}} crée une image qui passe en fullscreen au clic, {{fichier.mp3}} crée un lecteur audio, {{fichier.mp4}} crée un lecteur video etc...
on peut ajouter facilement des choses plus poussées en insérant des {{fichier.css}} ou {{fichier.js}}spécifiques.
L'appli offre certaines constantes accessibles de la même façon: {{BLEU}} change le fond en bleu, {{FULLSCREEN}} passe en fullscreen dès le chargement, {{FECHA}} ajoute la date du jour en espagnol...
les []
Les éléments de formulaire sont générés via des commandes gu genre {{app->flashcards("")}} qui ne sont pas super simple à mémoriser ou sexy à voir. Du coup, j'ai créé des aliases plus simples qui utilisent les crochets. Ainsi:
une case texte ? [texte à trouver]
Il faut accepter plusieurs réponses ? [réponse1+réponse2]
une liste déroulante ? [choix 1,choix 2, +bon choix,choix3]
Une case à cocher ? []texte d'une case à ne pas cocher], [+]texte d'une à case cocher]
un verbe à conjuguer ? [conjugaison:llamo,llamas,llama,llamamos,llamáis,llaman]
une phrase à ordonner ? [ordonne:La primera pelota está en la estantería.]
des flashcards ? [flashcards:texteface:textedos;texteface2:textedos2]
Une liste de mots à trouver ? [mots:textefr:texteesp;textefr2:texteesp2]
Un mot avec traduction ? [texte es=texte fr]
Un bouton pour aller au temps T d'un media ? [espana.mp3>0:07] ou [>0:07] si un seul media est présent sur la page.
Un bouton pour stocker les réponses de l'élève ? [envoyer]
Un enregistreur pour les élèves n'ayant pas d'appli d'enregistrement ? [enregistreur]
Le fait de ne jamais quitter le clavier supprime la plupart des clics et la perte de temps du passage entre clavier et souris. ça s'avère redoutable dès qu'on a un peu l'habitude: on ne s'occupe que du contenu sans jamais perdre de temps à chercher comment faire (friction d'utilisation minimale)
Tu as parlé de stocker les réponses des élèves ! ET LE RGPD ? 😱
T'inquiète, mon con de chef m'a suffisamment fait chier avec ça pour que je ne coure aucun risque (faire une recherche sur ce site avec le mot clé «j'abandonne» 😡):
rien n'est hébergé hors serveur,
je n'utilise rien que je n'ai fait moi-même (aucune lib notamment)
les données des formulaires remplis qui sont sauvegardées le sont dans un fichier anonymisé: à aucun moment l'élève ne renseigne son nom et à aucun moment une donnée perso n'est utilisée pour le nommage de fichiers. Quand l'élève a envoyé le formulaire, le site lui donne un code à fournir au prof afin qu'il ait accès à la copie.
J'utilise Documentos depuis 2018 et je le modifie régulièrement. L'utilisation au quotidien est top et lors du confinement, je n'ai pas eu à changer grand-chose pour que le distanciel soit possible... je pouvais fournir presque en temps réel et mes élèves ont pu bosser dès les premières minutes de confinement sans être déroutés et depuis n'importe quel appareil (là où l'ENT était à genoux dès 8:10)
Pas de lien ?!
Je ne fournis pas le code de Documentos pour plusieurs raisons:
c'est codé pour moi, avec mes habitudes... ça peut ne pas convenir à d'autres
c'est fait pour l'espagnol: on peut l'adapter, mais faut coder
il y a toujours des bugs par ci par là: je m'en accommode parce que je n'ai pas le temps de coder plus que ça et que ça ne touche pas le côté élève... mais ce serait chiant pour un autre.
j'ai beau essayer de maintenir la cohérence et la logique du code, le patch à la truelle nécessite de reprendre certains aspects.
pas de lien de démo car les documents fournis aux élèves sont copyrightés et que je ne veux pas d'emmerdes avec les éditeurs de bouquins
Unicode, c'est bien joli, mais c'est chiant à coller quand t'en as besoin. Du coup, tu lâches l'affaire.
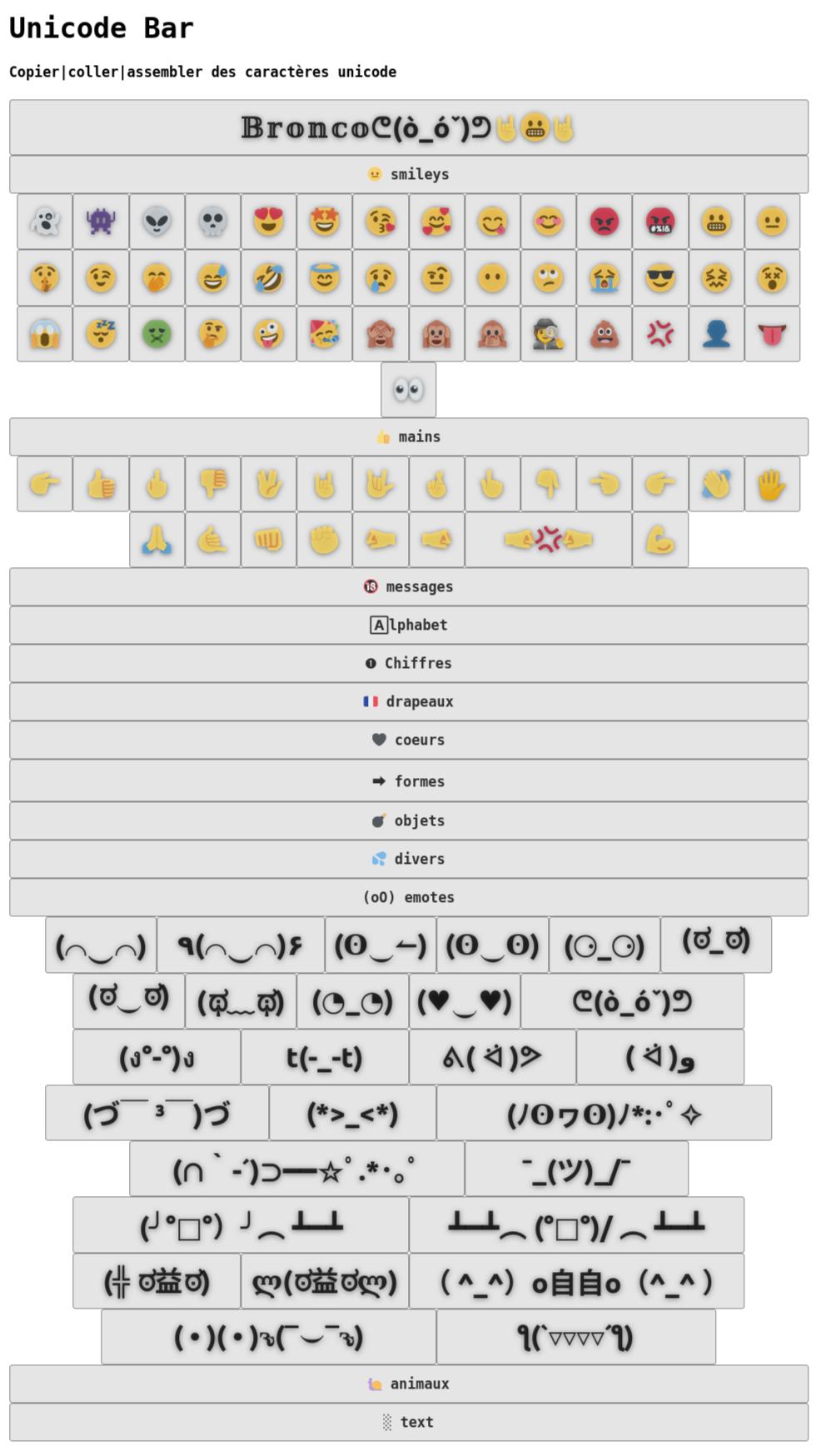
Bon, ben j'ai bricolé une page pour copier ces caractères qu'on utilise le plus.
Le but est de copier rapidement dans le presse-papier le (ou les) caractères unicode désirés.
Quand on clique sur un caractère il se passe deux choses:
🥇 ledit caractère est copié dans le presse-papier
🥈 il est également ajouté à la suite dans le bouton du haut qui donne la possibilité de cumuler plusieurs caractères de suite. (clic sur le bouton copie le contenu du bouton, double-clic l'efface)
Et pour configurer ?
Vous noterez que les chaînes peuvent n'être qu'un seul caractère unicode ou toute une série, si vous en utilisez régulièrement.
Comme c'est du html+js+css, pas besoin d'un serveur, on peut l'utiliser en local. 🎉
Ok, mais à quoi ça sert en vrai ?!
Ben je sais pas moi ! Vu que vous pouvez mettre les caractères/chaînes que vous voulez, ça peut servir pour les matheux (coucou les profs) qui ont besoin des symboles de math simplement ou ponctuellement , en musique, ou en électronique... explorez unicode !
Si toi aussi tu veux te faire un petit bookmarklet pour envoyer des données de la page courante vers un autre site, alors tu vas kiffer 😍 parce que ce petit bout de code te permet de le faire sans rien coder 😎.
Heing ?! 🤨
J'explique:
Si on veut pouvoir:
rechercher une sélection sur un site particulier (genre sur wikipedia, jeux videos.com, allocine...) ,
envoyer le titre de la page en cours et/ou son URL vers un site qui va s'en servir (par exemple pour bookmarker la page en cours),
alors ça peut se faire ici.
Fais voir ?
Voici deux exemples:
Quid ?
Pour faire simple,
on donne un nom au bookmarklet,
on choisit les données qui doivent être envoyées,
on spécifie l'URL vers laquelle elles doivent être envoyées.
Le bookmarklet est généré en temps réel et une fois les réglages faits, il suffit de glisser-déposer le lien du bas.
J'ai ajouté la possibilité de modifier la variable permettant de passer les données; en effet, duckduckgo utilisera q=[recherche] mais un autre site pourra demander query=[recherche]...
De plus, on peut spécifier de ne pas utiliser le format URL?variable=[donnée] mais URL/[donnée] pour les sites ayant une rewriteurl (comme wikipedia qui exige un format fr.wikipedia.org/wiki/[RECHERCHE] )
Enfin, si vous spécifiez une URL contenant déjà des paramètres GET (comme mespagesquejaime.com/ajouter.php?user=MOI&apikey=321fd5613e32), le script le prendra en compte et les nouveaux paramètres s'ajouteront correctement
( mespagesquejaime.com/ajouter.php?user=MOI&apikey=321fd5613e32&title=mon cul sur la commode&url=www.monculsurlacommode.fr )
Exemple ?
Vous pouvez essayer de générer un bookmarklet pour rechercher directement la sélection sur youtube:
donnez le nom «rechercher sur youtube»
cochez le premier item : «le texte sélectionné» et renommez la variable en «search_query»














 )
)











 )
)